2022-15-03: Since this was posted the CDC has updated how county level diabetes prevalance is calculated. The data presented here is using previous calcualtions and may no longer be correct. More can be read here
Abstract
Diabetes is growing at an epidemic rate in the United States. In North Carolina alone, diabetes and prediabetes cost an estimated $10.9 billion each year (American Diabetes Asssociation, 2015). This post introduces the exploration of the Diabetes epidemic in North Carolina. Through a series of posts this project will examine various public data available on diabetes and explore possible solutions to address the rise of diabetes in North Carolina. This investigation stems from the Capstone project of my Health Care Informatics Masters program. This post will answer the following questions:
What is the overall trend of diabetes prevalence in the United States?
What is the trend of diabetes at a State Level and how does diabetes prevalence vary by state and region?
How do trends in diabetes prevalence vary across counties of North Carolina?
In which counties of North Carolina does the largest change in diabetes prevalence occur?
How does change in diabetes prevalence compare between rural and urban counties?
Enviroment
This section contains technical information for deeper analysis and reproduction. Casual readers are invited to skip it.
Packages used in this report.
Code
# Attach these packages so their functions don't need to be qualified: http://r-pkgs.had.co.nz/namespace.html#search-pathlibrary(magrittr) # enables piping : %>%library(dplyr) # data wranglinglibrary(ggplot2) # graphslibrary(tidyr) # data tidyinglibrary(maps)library(mapdata)library(sf)library(readr)
Definitions of global object (file paths, factor levels, object groups ) used throughout the report.
Code
#set ggplot themeggplot2::theme_set(theme_bw())
Data
The data for this exploration comes from several sources:
The Diabetes data set for state and county levels were sourced from the US Diabetes Surveillance System; Division of Diabetes Translation - Centers for Disease Control and Prevention. The data was downloaded one year per file, and compiled into a single data set for analysis.
The Diabetes data set for National level data were sourced from the CDC’s National Health Interview Survey (NHIS)
The list of rural counties was taken from The Office of Rural Health Policy, the list is available here
Code
# load the data, and have all column names in lowercasenc_diabetes_data_raw <-read_csv("https://raw.githubusercontent.com/mmmmtoasty19/nc-diabetes-epidemic-2020/62bdaa6971fbdff09214de7c013d40122abbe40d/data-public/derived/nc-diabetes-data.csv") %>%rename_all(tolower)us_diabetes_data_raw <-read_csv("https://github.com/mmmmtoasty19/nc-diabetes-epidemic-2020/raw/62bdaa6971fbdff09214de7c013d40122abbe40d/data-public/raw/us_diabetes_totals.csv" ,skip =2)rural_counties <-read_csv("https://github.com/mmmmtoasty19/nc-diabetes-epidemic-2020/raw/b29bfd93b20b73a7000d349cb3b55fd0822afe76/data-public/metadata/rural-counties.csv")county_centers_raw <-read_csv("https://github.com/mmmmtoasty19/nc-diabetes-epidemic-2020/raw/b29bfd93b20b73a7000d349cb3b55fd0822afe76/data-public/raw/nc_county_centers.csv", col_names =c("county", "lat","long"))diabetes_atlas_data_raw <-read_csv("https://raw.githubusercontent.com/mmmmtoasty19/nc-diabetes-epidemic-2020/b29bfd93b20b73a7000d349cb3b55fd0822afe76/data-public/raw/DiabetesAtlasData.csv" ,col_types =cols(LowerLimit =col_skip(), UpperLimit =col_skip(),Percentage =col_double()), skip =2)
Code
# load in both US State Map and NC County Mapnc_counties_map_raw <-st_as_sf(map("county",region ="north carolina", plot =FALSE,fill =TRUE)) %>%mutate_at("ID", ~stringr::str_remove(.,"north carolina,"))state_map_raw <-st_as_sf(map("state",plot =FALSE,fill =TRUE ))nc_cities <-st_as_sf(read_csv("https://github.com/mmmmtoasty19/nc-diabetes-epidemic-2020/raw/b29bfd93b20b73a7000d349cb3b55fd0822afe76/data-public/metadata/nc_cities.csv"),coords =c("long", "lat") ,remove =FALSE ,agr ="constant" ,crs =4326)
Data Manipulation
The combined data used in this anaylsis can be downloaded here. The only tweaks done here are to combine the rural counties column, and the data for creating maps.
#join US totals to NC data nc_diabetes_data <- nc_diabetes_data_raw %>%mutate_at("county", ~stringr::str_replace_all(.,"Mcdowell","McDowell")) %>%mutate(rural = county %in% rural_counties$rural_counties ) %>%mutate_at("county",tolower) %>%left_join(us_diabetes_data)nc_counties_map <- nc_counties_map_raw %>%left_join(nc_diabetes_data, by =c("ID"="county")) %>%left_join(county_centers, by =c("ID"="county")) %>%rename(center_long = long ,center_lat = lat)state_map <- state_map_abb %>%left_join(diabetes_atlas_data, by =c("ID"="State")) %>%rename_all(tolower)
Overall - National Level
Code
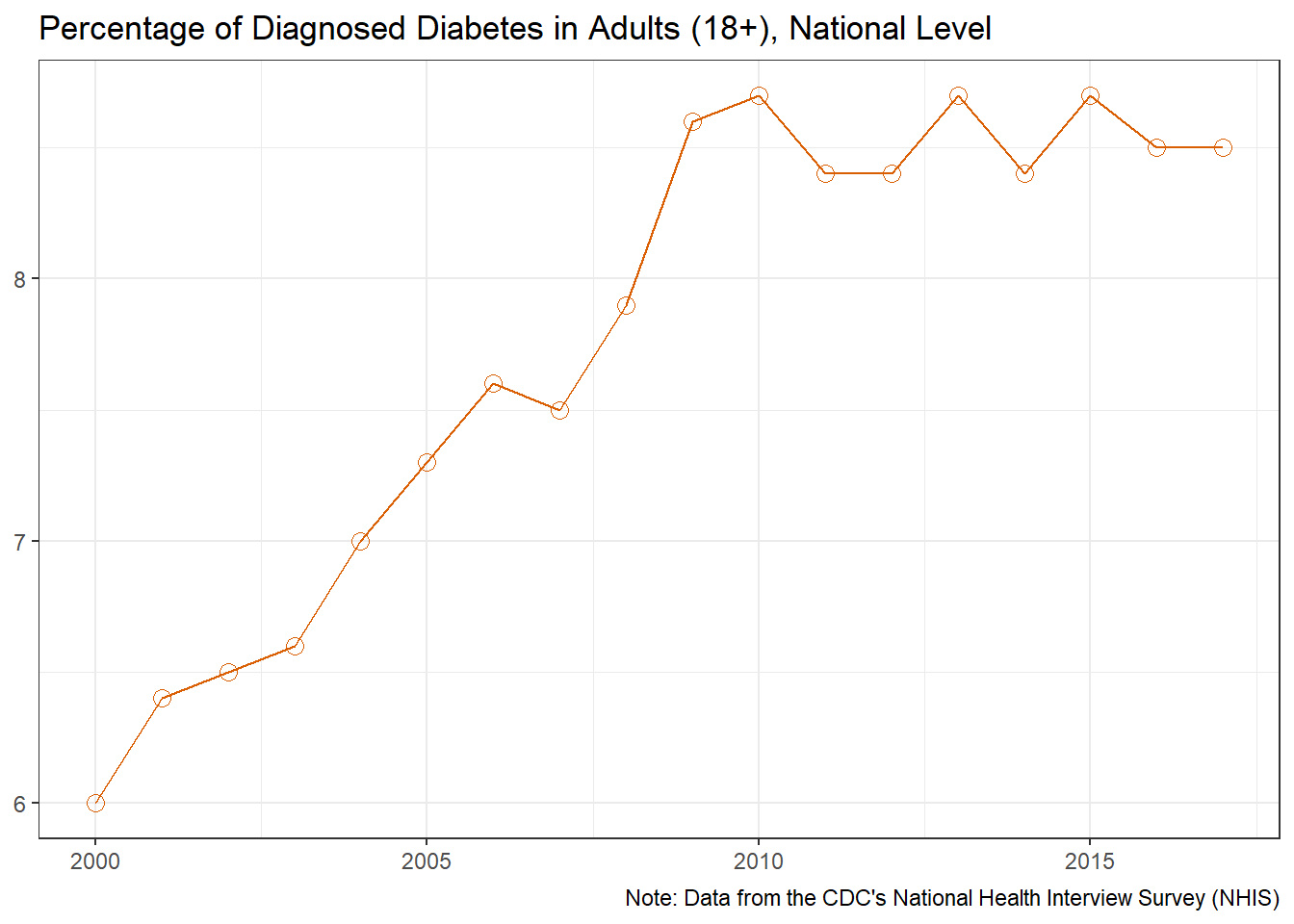
us_diabetes_data <- us_diabetes_data %>%mutate(change =lead(us_pct) - us_pct ,change =if_else(change >0, TRUE, FALSE) ) %>%mutate_at("change", ~stringr::str_replace_na(.,"NA"))o_g1 <- us_diabetes_data %>%ggplot(aes(x = year, y = us_pct)) +geom_line(color="#D95F02") +# geom_line(aes(color = change, group = 1)) +geom_point(shape =21, size =3,color="#D95F02") +# geom_point(aes(color = change),shape = 21, size = 3) +scale_color_manual(values =c("TRUE"="#D95F02" ,"FALSE"="#7570B3" ), guide =FALSE) +labs(title ="Percentage of Diagnosed Diabetes in Adults (18+), National Level" ,x =NULL ,y =NULL ,caption ="Note: Data from the CDC's National Health Interview Survey (NHIS)" )o_g1
Overall, the national average for diagnosed diabetes sharply rose through the early 2000’s, leveling off around 2010. These numbers however, are estimates based on the self-reported response to the CDC’s National Health Interview Survey, and do not represent the actual confirmed diagnoses. The CDC estimates that 1 in 5 adults have undiagnosed diabetes, therefore the numbers reported by the NHIS are likely to underestimate the true prevalence (Centers for Disease Control and Prevention, 2020).
Overall - State Level
State and County level data on diabetes prevalence are taken from the CDC’s Behavioral Risk Factor Surveillance System (BRFSS). These results are based on the question “Has a doctor, nurse, or other health professional ever told you that you have diabetes?”. Women who only experienced diabetes during pregnancy were excluded from the counts. The BRFSS is an ongoing, monthly telephone survey of the non-institutionalized adults (aged 18 years or older) in each state. The year 2011 saw a major change to the methodology of the survey, which started to include homes without a landline phone. This change was expected to increase coverage of lower income, lower educational levels, and younger age groups, because these groups often exclusively rely on cellular telephones for personal communication.(Pierannunzi et al., 2012)
Code
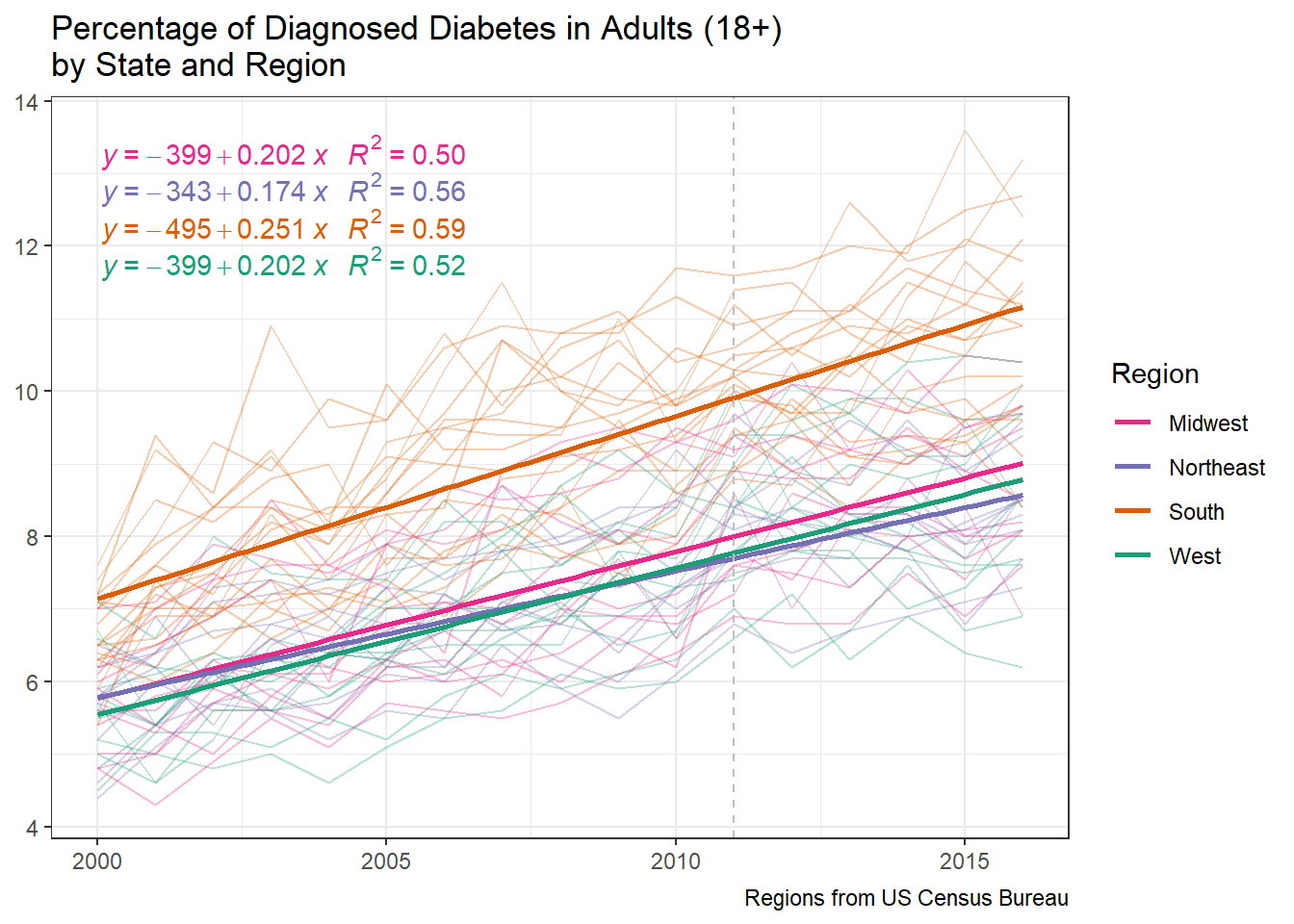
s_g1 <- state_map %>%st_drop_geometry() %>%ggplot(aes(x = year, y = percentage, color = region)) +geom_line(aes(group = id ),alpha =0.3,na.rm =TRUE) +geom_smooth(method ="lm", se =FALSE) + ggpmisc::stat_poly_eq(formula = y ~+ x ,aes(label =paste(..eq.label.., ..rr.label.., sep ="~~~")), parse =TRUE) +geom_vline(xintercept =2011, linetype ="dashed", color ="gray") +scale_color_brewer(palette ="Dark2" ,direction =-1 ,labels = snakecase::to_title_case ) +labs(title ="Percentage of Diagnosed Diabetes in Adults (18+) \nby State and Region" ,x =NULL ,y =NULL ,color ="Region" ,caption ="Regions from US Census Bureau" ) s_g1
The above graph shows diabetes prevalence trends by state, grouped into regions based on the US Census classification regions. While all regions of the United states show positive growth in diabetes prevalence, the south exhibits a slightly higher growth rate, as well as the highest prevalence.
Code
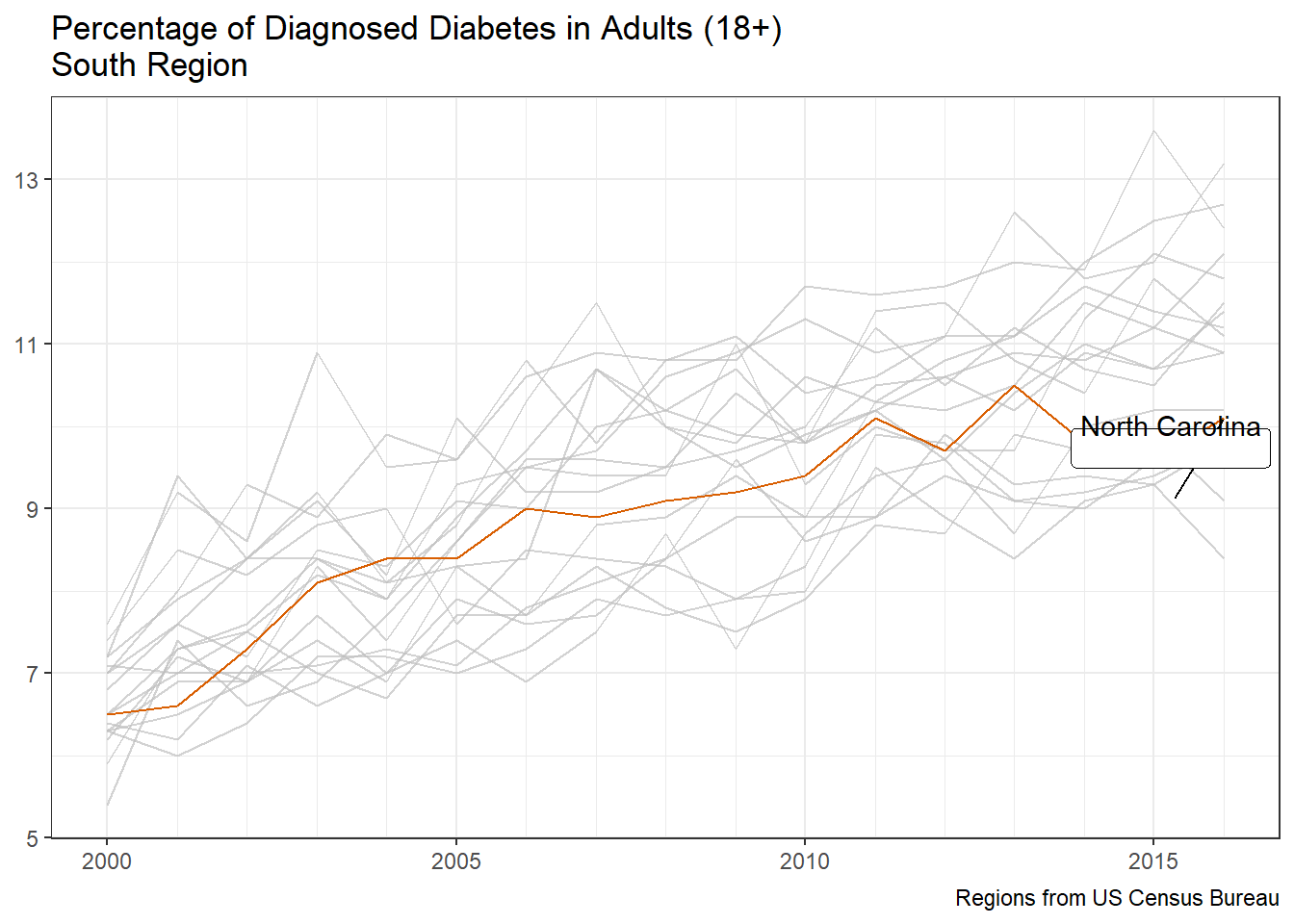
s_g2 <- state_map %>%st_drop_geometry() %>%filter(region =="south") %>%mutate_at("id", ~snakecase::to_title_case(.)) %>%ggplot(aes(x = year, y = percentage)) +geom_line(aes(group = id ),na.rm =TRUE, color="#D95F02") + gghighlight::gghighlight(id =="North Carolina", label_params =list(vjust =3)) +scale_y_continuous(breaks =seq(5,13,2)) +scale_x_continuous(minor_breaks =seq(2000,2016,1)) +labs(title ="Percentage of Diagnosed Diabetes in Adults (18+) \nSouth Region" ,x =NULL ,y =NULL ,caption ="Regions from US Census Bureau" ) +theme()s_g2
When focusing on the south region, North Carolina falls close to the middle of diabetes prevalence.
Overall - North Carolina
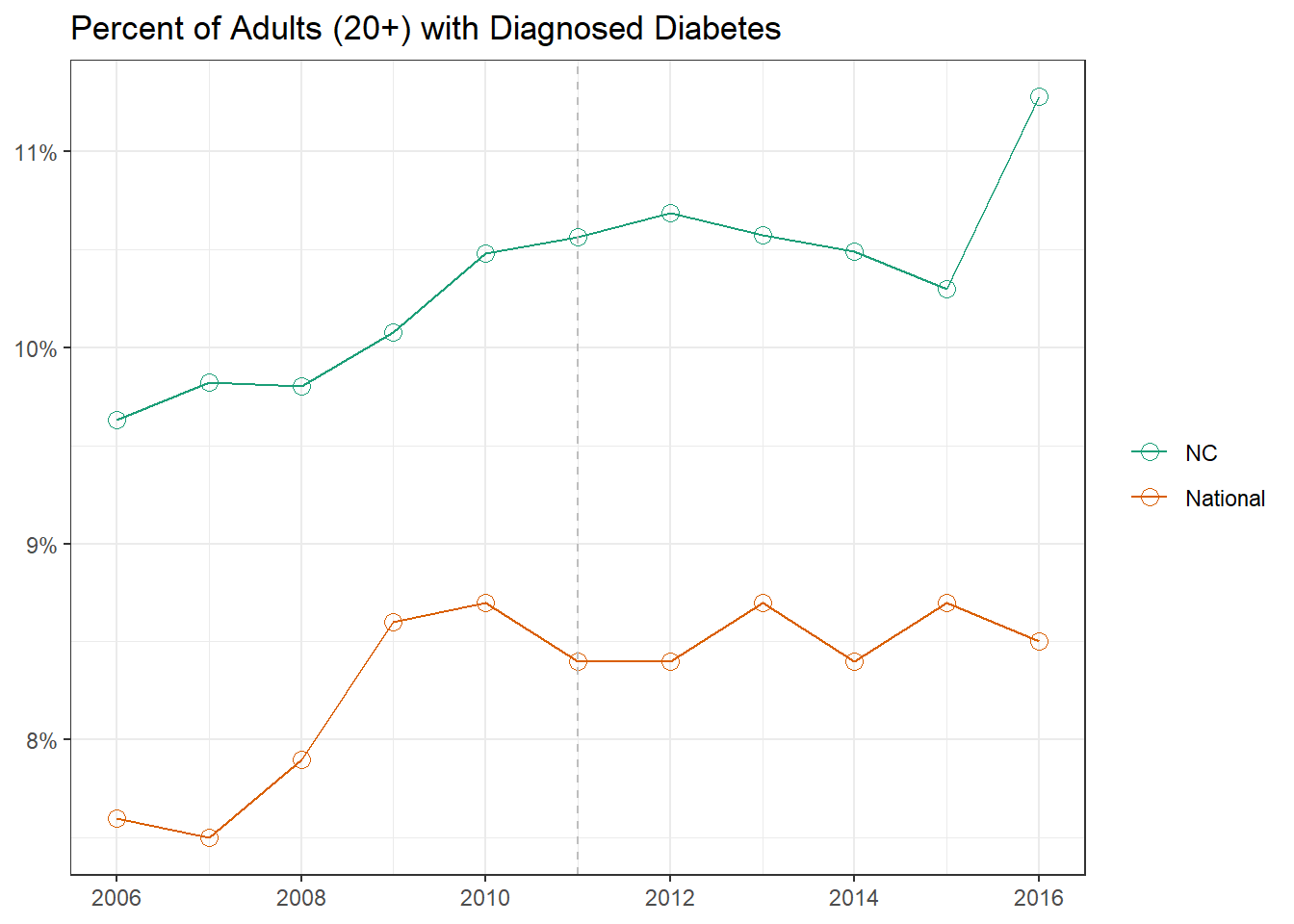
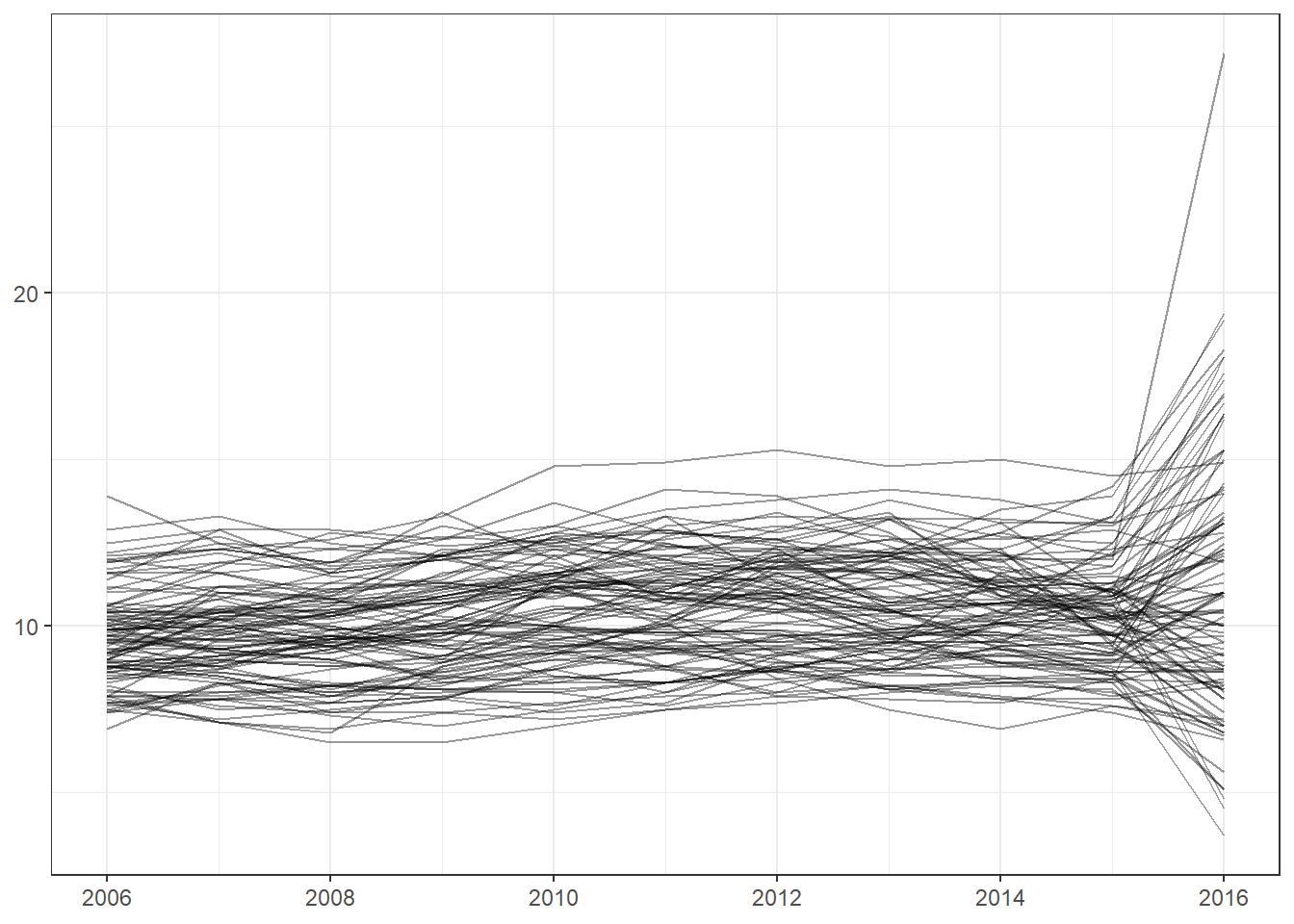
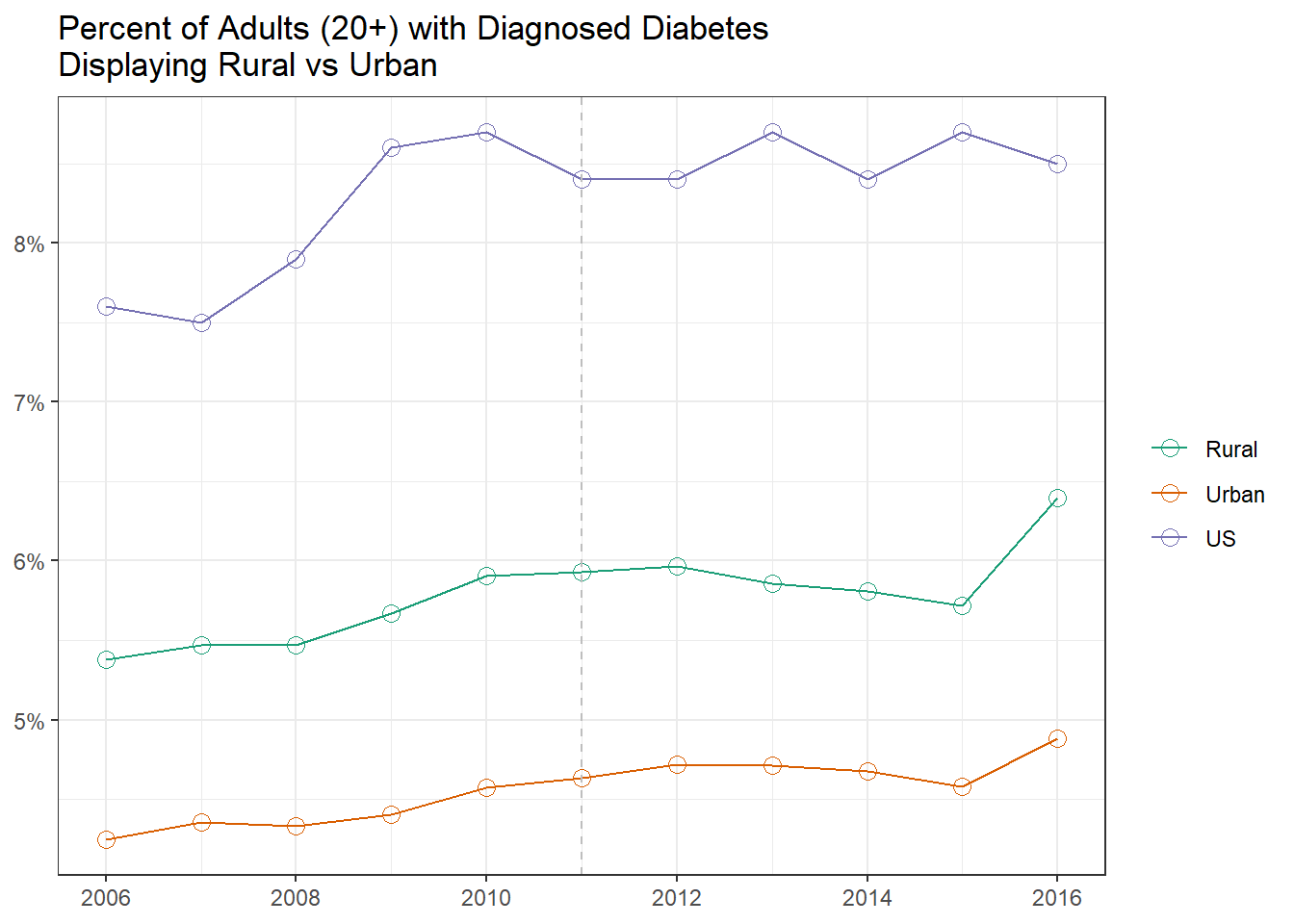
When examining the trajectory for North Carolina, we can see that it has been consistently higher than national average . We see that in 2016 there was a large spike in diagnosed cases; unfortunately this is the last available year so it is unclear whether the upward trend continues. The graph below compares state-level average to the national average. Notice that the trend line is slightly higher than in the previous graphs: this is due to the age cut offs used for National and State level data vs County Level data. Previous data used 18 years of age as a cutoff for classifying adults, whereas the county level data uses 20. Due to removing 18- and 19-year-olds from the population, who typically have less diagnosed cases of diabetes than those of older ages, the computed prevalence increases slightly.
We see a spike in 2016, the last year for which the data are available. However, we should be careful with our interpretation of this pattern, because the examination of the county-level trajectories reveals an aberration in the trend that requires a more rigorous investigation.
While all of North Carolina has a higher prevalence than the national average, rural counties have systematically higher prevalence of diabetes than urban counties. Note that after 2011 both Urban and Rural counties break the upward trend exhibited in the previous 5 years. This could be explained by the addition of cell phones to the BRFS Survey as many rural areas are often lower income areas and may only rely on a cell phone for communication. As mentioned previously there is an odd spike in case in 2016 that can’t be explained by current documentation. For the purpose of this evaluation 2016 will be excluded from the county level data since the odd trend can not be explained and no further data is available to determine if this is a real spike or could be attributed to methodology change or data quality.
County level data first became available in 2004, three years of data is used to arrive at these estimates. For example, the 2006 estimates were computed using the data from 2005, 2006, and 2007 BRFS survey rounds. The county-level estimates were based on indirect model-dependent estimates using Bayesian multilevel modeling techniques(Barker et al., 2013; JNK, 2003). This model-dependent approach employs a statistical model that “borrows strength” in making an estimate for one county from BRFSS data collected in other counties and states. Multilevel Binomial regression models with random effects of demographic variables (age 20-44, 45-64, >=65; race/ethnicity; sex) at the county-level were developed. Estimates were adjusted for age to the 2000 US standard population using age groups of 20-44, 45-64, and 65 or older(Klein & Schoenborn, 2001).
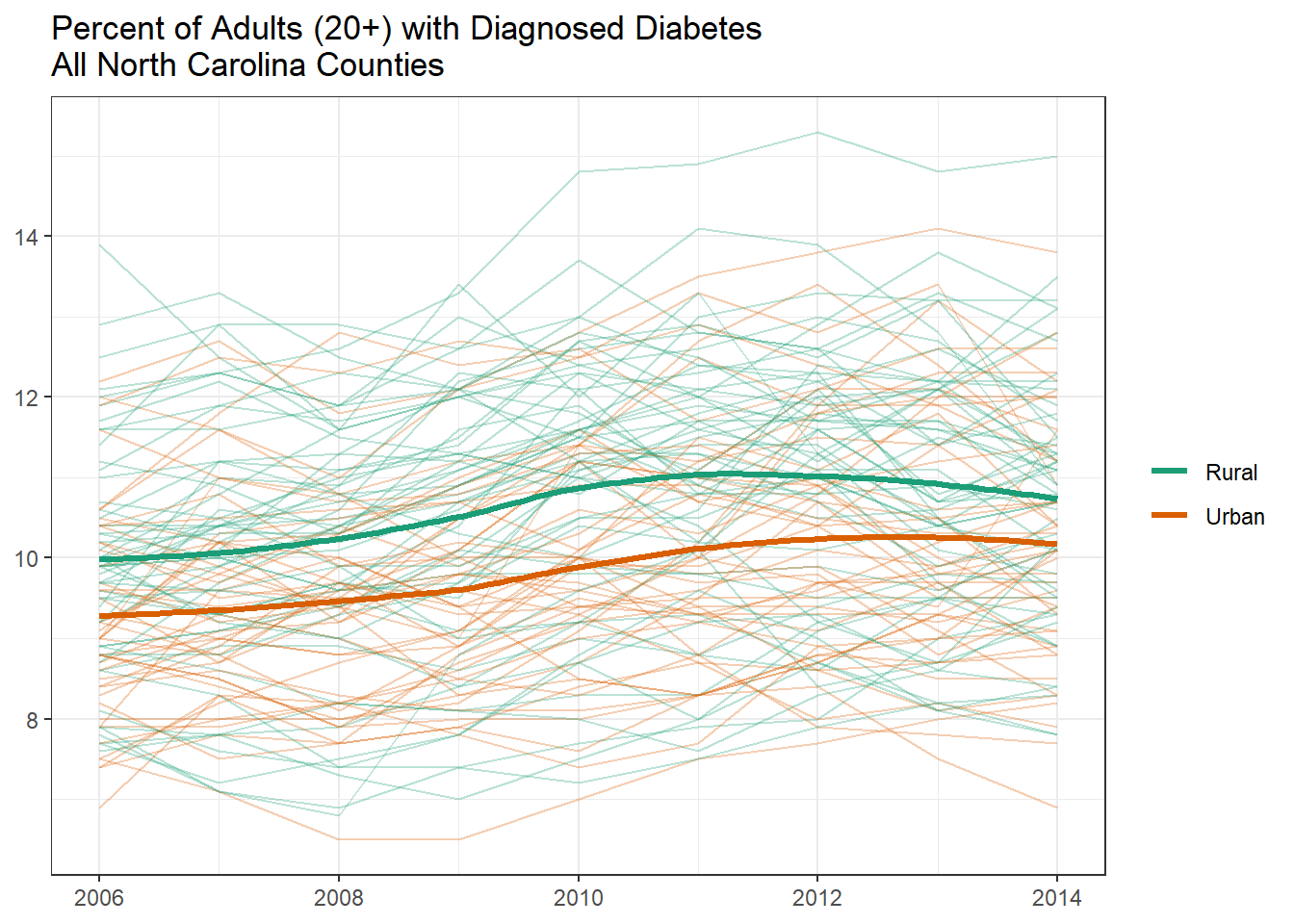
When viewing all county trend lines together, we see that the loess line for both urban and rural follows a similar trend for the time period.
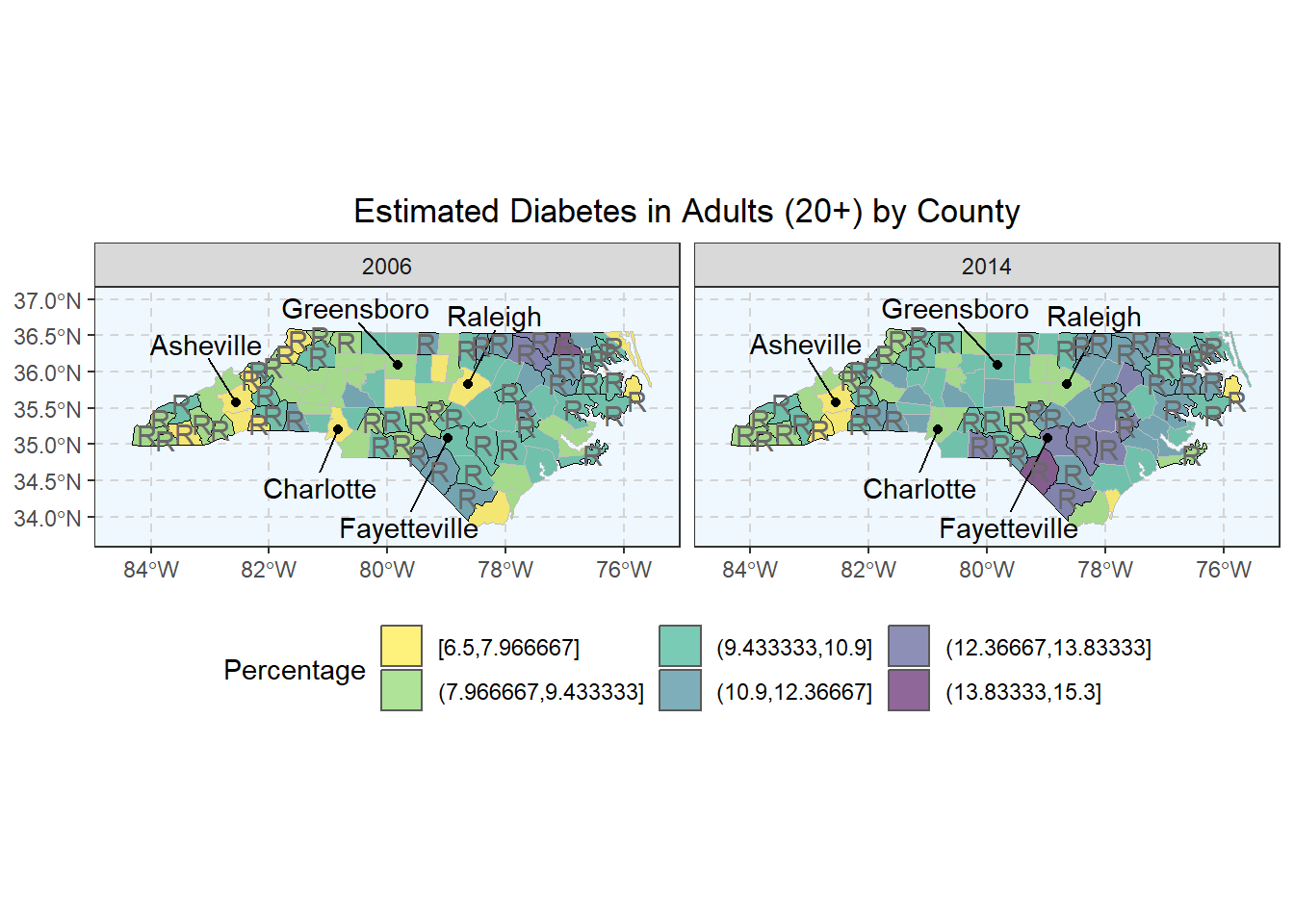
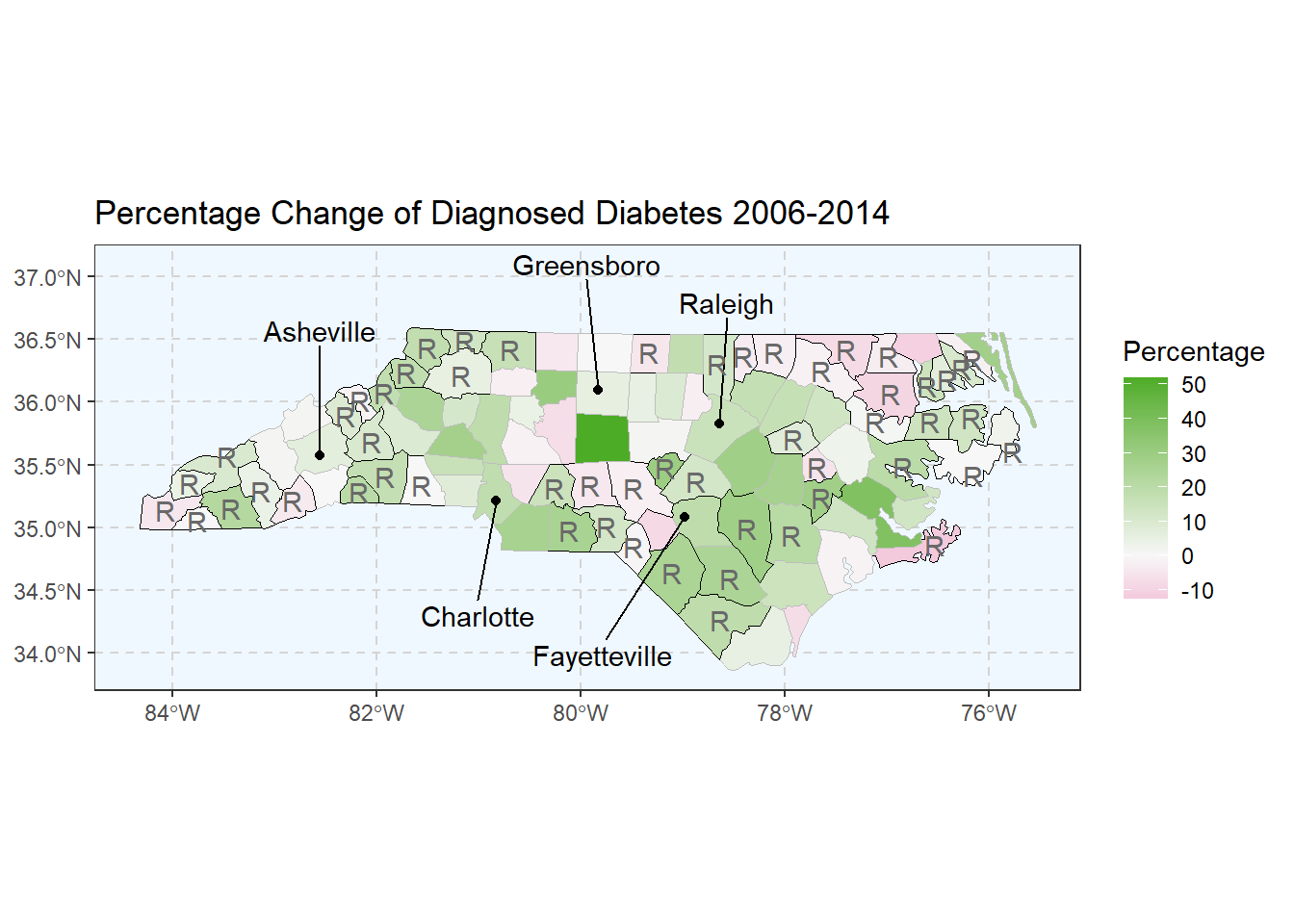
The following graphs displays the total estimated prevalence of Diabetes in each off the 100 North Carolina counties. To keep the scaling consistent between the graphs, we binned the estimates into 6 intervals of the same size. Rural counties are highlighted with a stronger border line as well as a letter “R” in respective geographic centers. These graphs allow us to view geographical clusters of diabetes prevalence.
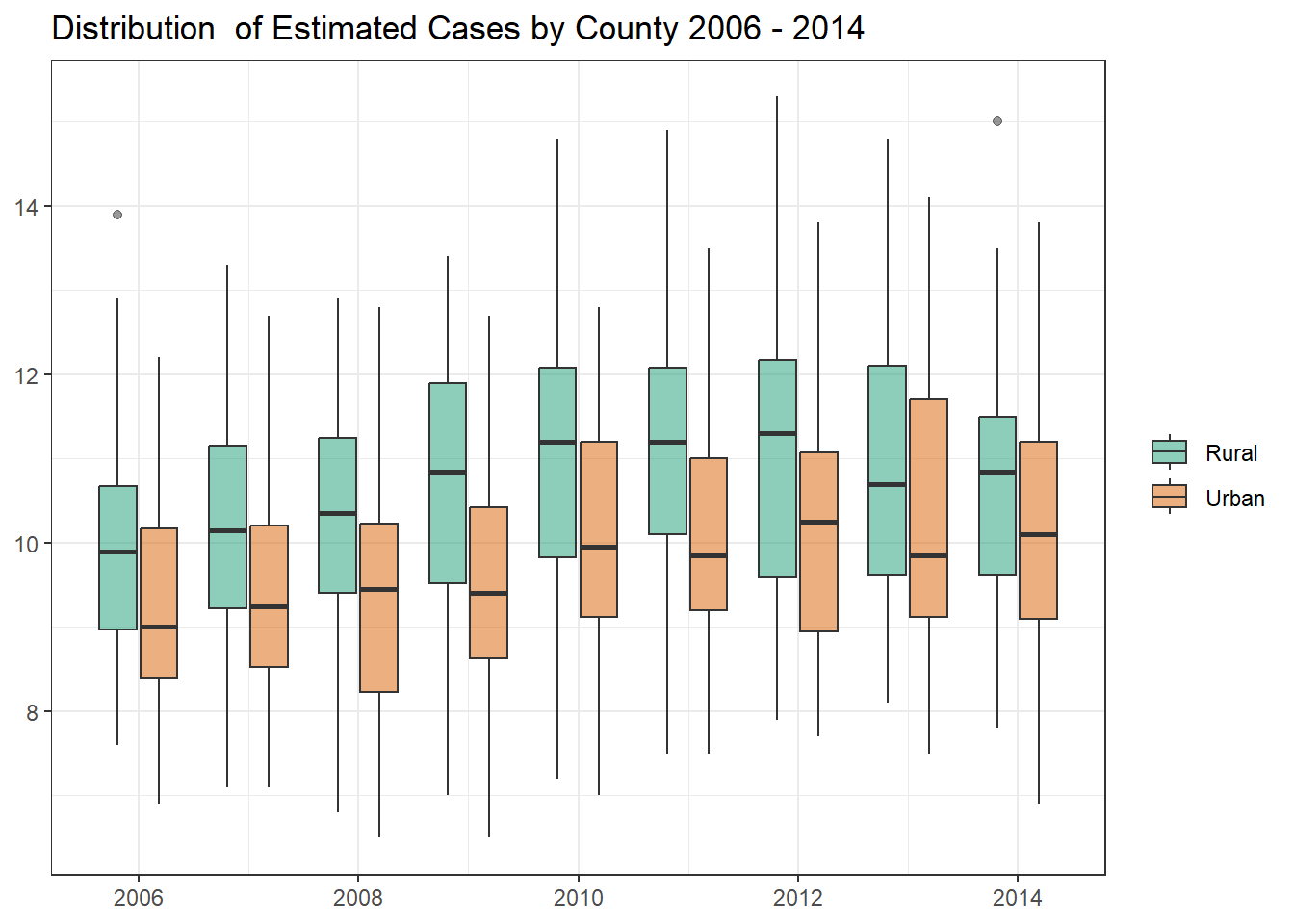
The following box plot displays the distribution of estimated cases by county from 2006 to 2014. For all years of current data the mean of rural counties is higher then that of their Urban counterparts.
Code
c_g1c <- nc_counties_map %>%mutate(rural =factor(rural ,levels =c(TRUE,FALSE) ,labels =c("Rural", "Urban") )) %>%filter(year <2015) %>%ggplot(aes(x = year, y = percentage, group =interaction(year,rural), fill = rural)) +geom_boxplot(alpha =0.5) +scale_fill_brewer(palette ="Dark2") +scale_x_continuous(breaks =seq(2004,2014,2)) +labs(x =NULL ,y =NULL ,fill =NULL ,title ="Distribution of Estimated Cases by County 2006 - 2014" )c_g1c
By County - Percent Change
The following graphs display the overall change in estimated prevalence between 2006 to 2014.
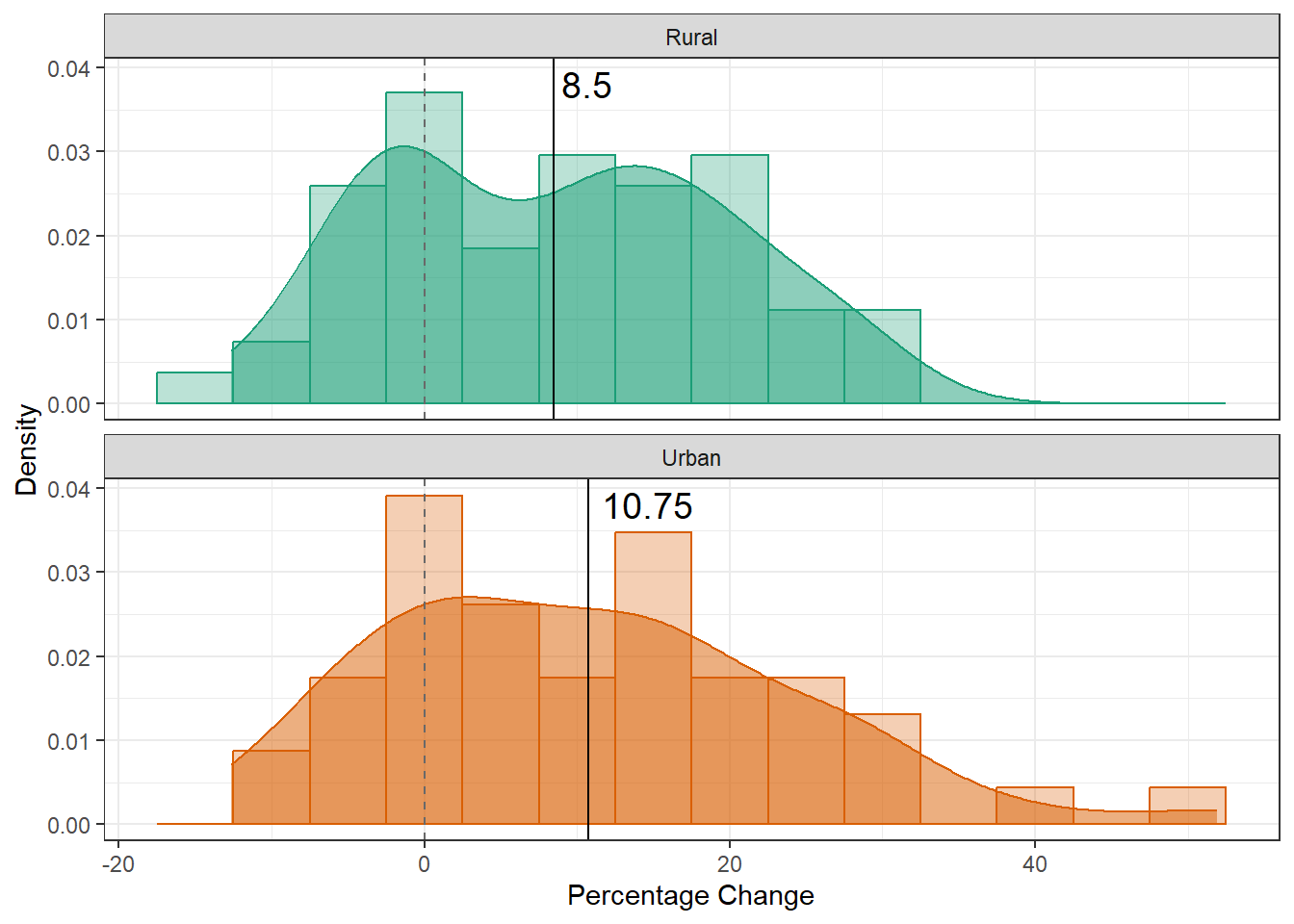
The following chart displays the density curve of the percentage change for both rural and urban counties. It is notable that the mean of change for Urban counties is actually higher than the mean for rural counties. However, we also see that most change for both regions is positive growth. In fact only 16 rural, and 10 Urban counties experienced negative change in the given time frame. While 35 rural and 34 urban counties experience growth in the same period.
The original hypothesis of this report was that rural counties were growing at a higher rate then there urban counterparts. Through out this post it has been shown that this hypothesis is incorrect, just being a rural county does not indicate diabetes growth, in fact the growth rate throughout North Carolina has been consistent. Further posts will explore other reasons for these trends, as the current post merely explores the trends and differences using data visualizations, a more rigorous and formal evaluation of these comparison is in order.
Barker, L. E., Thompson, T. J., Kirtland, K. A., Boyle, J. P., Geiss, L. S., McCauley, M. M., & Albright, A. L. (2013). Bayesian small area estimates of diabetes incidence by united states county, 2009. Journal of Data Science, 11(1), 269–280. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4537395/
Klein, R. J., & Schoenborn, C. A. (2001). Age adjustment using the 2000 projected u.s. population. Healthy People 2000 Stat Notes, 20, 1–9.
Pierannunzi, C., Town, M., Garvin, W., Shaw, F. E., & Balluz, L. (2012). Methodologic changes in the behavioral risk factor surveillance system in 2011 and potential effects on prevalence estimates. Morbidity and Mortality Weekly Report, 61(22), 410–413. https://www.cdc.gov/mmwr/pdf/wk/mm6122.pdf